Natural Language Inference for Hallucination Detection in RAG Responses
If you search online for ways to detect RAG response faithfulness, most posts recommend using an ‘LLM-as-a-judge’ approach. However anyone who has some statistical knowledge will have a doubt about using LLM as a judge to detect faithfulness. How can a model prone to hallucination detect hallucination? 🤔”

In this post, we’ll explore what “hallucinations” mean in the context of Large Language Models (LLMs). We’ll look at two kinds of LLMs and see which ones tend to hallucinate more often. Then, we’ll shift to a different approach that uses models less likely to hallucinate, introduce the idea of Natural Language Inference (NLI), and see how NLI can help check the faithfulness of RAG responses. Finally, we’ll look at how these ideas work in real-world production systems, more precisely in the example of the AIM usecase.
AutoEncoding Model vs AutoRegressive Models.
Large Language models can be divided into two categories based on how they are trained. We have auto regressive and auto encoding models.
Auto regressive models are trained with the next token prediction objective. Given the previous token in a sentence predict the next token. Typical examples of those models are the GPT model, and all model trained with the Llama architecture.
Auto encoding models are trained with fill the mask objective, when they are given an input sentence with a mask and they are trained to predict the masked word. While trained with that objective they learn text features and those features can be used later in sentence classification, or token classification or just to learn the text embeddings. They cannot generate text, which is why they are less prone to hallucinations.
Note that the only difference between autoregressive models and autoencoding models is in the way the model is pretrained. Therefore, the same architecture can be used for both autoregressive and autoencoding models.
Auto regressive models can hallucinate because they’re trained to predict plausible continuations, not factual correctness. Auto encoding models, on the other ends, are optimized for reconstructive understanding rather than free-form generation — making them more stable for discriminative tasks like NLI.”
source: Huggingface blog
Hallucinations
Large Language models especially those from the GPT and Llama family are auto regressive by Nature, they are next token predictors and use probabilities to predict the next token given previous token, due to that nature they are prone to hallucinations (or false or misleading information presented as fact.)
This happens because the model’s objective is to generate the most probable continuation of text rather than to verify the factual accuracy of what it produces, meaning that when reliable context or evidence is missing, it may confidently generate information that sounds plausible but is actually incorrect.
In the RAG setting hallucination is when the LLM generated answers is not supported by the retrieve context.
With the definition of the hallucination let present an approach use by auto encoding model to avoid them.
Natural Language Entailment or Natural Language Inference(NLI)
Definition: Sources 1, 2
Textual Entailment or Natural Language Inference is an NLP task of deciding, given two text fragments, whether the meaning of one text can be inferred (entailed) from another text.
Mathematically, it can be formalized this way: Given two fragments of texts, a hypothesis \(h\) and a text \(t\): A text \(t\) entails a hypothesis \(h\) if \(h\) is true in every circumstance in which \(t\) is true.
Example:
Text: Eyeing the huge market potential, currently led by Google, Yahoo took over search company Overture Services Inc last year.Hypothesis: Yahoo bought Overture.Entailment: True
Text: The National Institute for Psychobiology in Israel was established in May 1971 as the Israel Centre for Psychobiology by Prof. JoelHypothesis: Israel was established in May 1971.Entailment: False.
How does that work in practice?
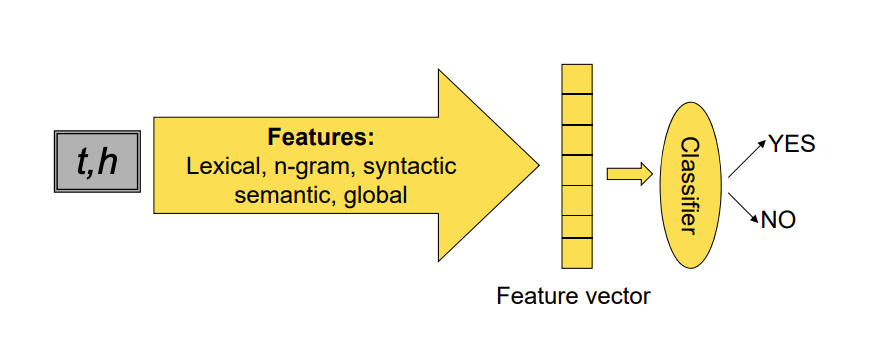
Natural Language Entailment
Features model both similarity and mismatch:
- Classifier determines relative weights of information sources
- Train on development set and auxiliary t-h corpora
In practice Natural Language entailment is done as a classification task. The text and the hypothesis are passed to a model which will learn their representation in a feature space, and then a classification layer is added at the end to predict whether there is entailment between those two texts.
In the early ages of NLP the feature was learned via N-grams or lexical features, but currently auto encoding models have proven themselves useful for those tasks. In many tasks for the moment we use cross encoder models trained on large NLI datasets.
Cross Encoders
A cross encoder model is a auto encoding model from the BERT familly, that take as input a pair of two sentence and generates a vector output. Depending on how it was trained that output can represents a similarity score between the two sentence, or as for our use case it output the entailment probability between those two sentences.
So Given a hypothesis, and a text, a cross encoder is trained to predict if the text is entailed by the hypothesis. To achieve that the model predicts 3 different probabilities which are the probability of entailment, contradiction or neutrality between the text and the hypothesis.
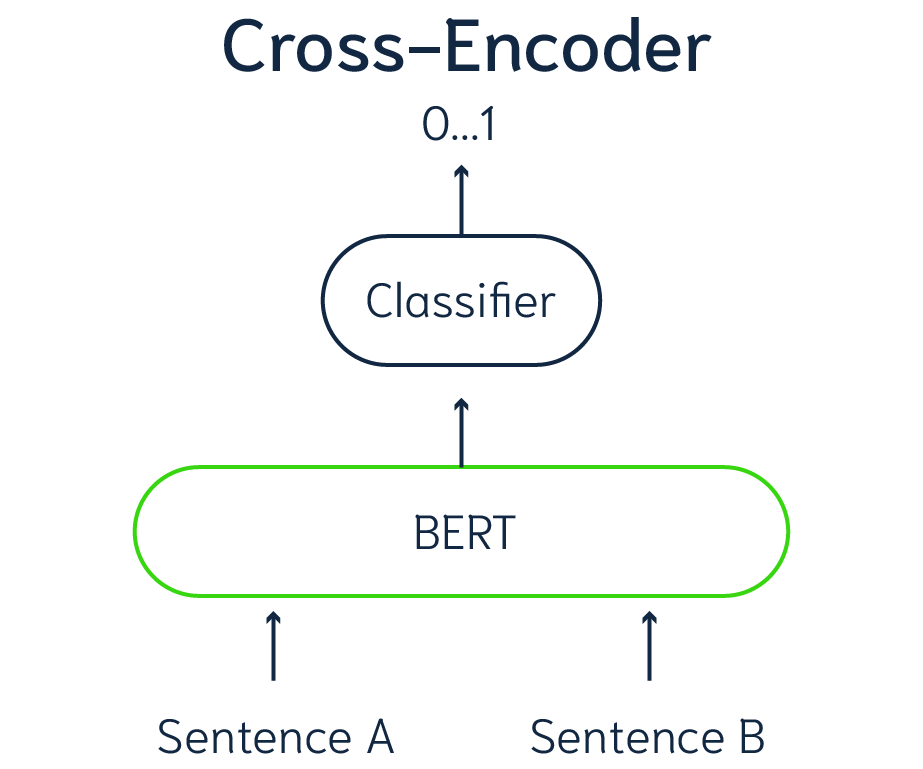
Reference: Mlivus Post on Detecting Hallucinations.
NLI as Faithfulness checks.
The natural language inference approach is used widely in fact verification. Given a fact and a bunch of reference text, can we find one reference that confirms or declines the fact?
That same approach has been used in RAG evaluation, given an answer and the context, the task similar to the NLI one is to check if the context supports, or contradicts the answer. When the context contradicts an answer we can say that the answer has been hallucinated.
For RAG there are two approach to check the faithfulness of a generated answer against the chunk,
One approach is to split the answer in sentences and check each sentence if it is supported by the chunk. his approach is the one used in the SumaC Paper.
The second approach we use the answer and check if the answer without splitting it into chunk it is supported or not supported by the chunk.
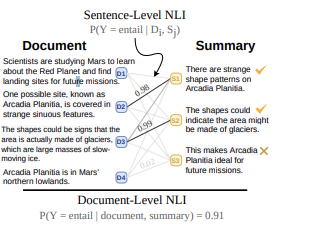
Given the answer split into sentences and the chunks used to generate the answers.
Then a cross encoder model computes the entailment score for each sentence of answer vs each sentence in the chunk to generate a probability distribution of [entailment, contradiction, neutrality]
So if an answer has 4 sentences and you have 2 chunks, we end up with 4 x 2 pairs that are sent to the cross encoder.
| Sentence 1 | Sentence 2 | Sentence 3 | |
|---|---|---|---|
| Chunk 1 | [(Eij, Cij, Nij)] | (Eij, Cij, Nij), | (Eij, Cij, Nij)— |
| Chunk 2 | [(Eij, Cij, Nij)] | (Eij, Cij, Nij), | (Eij, Cij, Nij) |
Those scores are saved in a matrix which is called entailment matrix.
To reduce the scores on answer level it depends on what we are trying to achieve.
If at least one combination chunk, sentence is contradictory the answer is marked as hallucinated.
Depending on the use case you can use different approaches to combine the probability distribution to have one score per answer.
Conclusion
As the encoder model is not auto regressive this approach will not be prone to hallucination but it can have flaws depending on how the model was trained. We cannot say it is also 100% accurate, but it has shown its efficiency in practice.
Another advantage is the cross encoder model is small and can be fine tuned on a dataset of your choice.
Provenance Approach : Ref
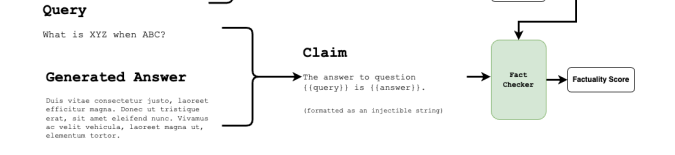
The provenance approach uses a NLI cross encoder but with a slight difference from the SummaC approach.
They use both the question and the answer to compute a factuality score.
They generate an input by combining the Answer and the question with the following claim:
“The Answer to question
And then they combine that claim with each chunk used to generate the answer and put it as an input to a Transformer model T5 Model that returns the factuality score.
Later the answers are combined using the same approach we used in the SummaC approach. If there is at least one chunk that contradicts the answer then the whole answer is marked as hallucinated.
Enough Talk, the code!
The context of this project is a QA system I am building on top of the Halifax intermediaries website, the goal of the project is to build a tool that help broker to find answer to question they have about Halifax products. They are question varies from simple question to large and complicated questions.
We will use the data which consist of a question, the chunks used to generate the answer, and the generated answer.
Then we will consider two approach the first one is where we will split the generated answer into sentence and compute the NLI Score between each sentence and the chunk used to generate the answer.
In the second approach we will use the Answer as one block and compare the NLI score with each chunk used to generate it.
The model used: We will be using the cross encoder named tals/albert-xlarge-vitaminc-mnli from huggingface.
The model is a Bert model train on a dataset that contains more than 450,000 claim-evidence pairs from over 100,000 revisions to popular Wikipedia pages, and additional “synthetic” revisions.
Experiments
Split by sentence.
In the first iteration from 136 questions: We split the answer into sentences and we compare each sentence to the chunk and get the entailment score, which comes as a probability distribution over 3 variable: entailment, contradiction and neutrality.
Here is an example of the score produce after splitting the answer by sentence.

Each row in the table bellow contains a chunk returned for the question: I have a client who has a buy to let mortgage which is rented out, will Halifax use the profits from this for resi affordability purposes?, the column contain each sentence in the generated answer. The cell value is a array [x1, x2, x3] x1: is the probability of entailment, x2: is the probability of contradiction x3 . is the probability of neutrality.
In the second table we pick the maximum value for in each cell. If the maximum is x1 the color of the cell is green and that means entailment. If the maximum is x2, we put the color red which mean contradiction, if it x3 we put the color green which mean neutrality.

An answer is marked hallucinated if there is at least one contradictory statement between a sentence and the chunk with a probability greater than 50%.
With this approach 40 answers out of 146 are marked hallucinated(mean they have a least one contradictory statement.)
The problem with this is that it is very harsh, I have seen some sentence which were contradicted by one chunk and supported by other chunks, reason why I decided to try the second approach.
Using the Answer without Split
In this approach the the answer is not split by sentence, each cell contains the contradiction probability between the answer and the chunks.
In the table the row remains the chunks and the headers is the answer. The cell are colored with the same logic as in the first section.
An answer is marked invalid using the same rule as the first section.

Limitation of the NLI Approach
While this approach is less prone to hallucination, it suffer of the limitation of the NLI model used. The model was not trained on specific domain, we may need to collect data and fine tune it on your domain to get a better accuracy on your domain data.
Conclusion
Detecting hallucinations in RAG systems isn’t just about finding wrong answers, it’s about checking whether the model’s answers are truly grounded in the retrieved context. While the “LLM-as-a-judge” approach sounds tempting, it’s a bit of a paradox: using a model that can hallucinate to detect hallucination.
The Natural Language Inference (NLI) approach offers an alternative. Instead of asking another LLM for its opinion, we use a smaller, more stable auto encoding model (like BERT or ALBERT) to check whether each generated statement is entailed or contradicted by the retrieved text.
In practice, this can be done sentence by sentence (as in SummaC) or at the full-answer level (as in the Provenance approach). It’s lightweight, interpretable, and much easier to adapt to specific domains like financial QA systems.
Of course, it’s not perfect. NLI models still need domain fine-tuning to capture the nuances of specialized data. But once tuned, they provide a practical and trustworthy way to measure faithfulness in RAG responses.
In short, NLI turns hallucination detection into a fact-checking problem one that’s explainable, measurable, and much less prone to the same issues we’re trying to fix.
References
- Hugging Face Blog — Autoregressive and Autoencoding Models Overview
- C. Manning, B. MacCartney . Modeling Semantic Containment and Exclusionin Natural Language Inference
- Ageno, A. Textual Entailment: Natural Language Inference Approaches.
- Milvus Blog — Detecting Hallucinations in RAG-Generated Answers.
- Vectara — Hallucination Evaluation Model (T5-Based Cross Encoder).
- Tals — ALBERT-XLarge VitaminC MNLI Model.
- Phillipe Laban et al. (2021). SummaC: Re-Visiting NLI-based Models for Factual Consistency Evaluation.
- Tanner Sorensen. (2024). Provenance Approach for Hallucination Detection in RAG Systems.
Comments