Designing Trustworthy RAG Systems. Part One: A Step By Step Waterfall Evaluation Approach

You have written that RAG pipeline, you have chunked, you have ingested the document in your favorite vector database using your best embedding model, and you have retrieved and generated an answer using your LLM. How do you know that you are sending the correct answer to your users and your RAG system is really bringing value to them? If you have been building RAG systems, that question is familiar to you. In this post we will try to answer that question by summarizing a few tips we learned last year while building the AIM project.
AIM stands for AI for Mortgages Intermediaries. It is a RAG solution built on top of the halifax-intermediairies website and mortgages product documentation contained in pdf documents.
The aim of the project is to give mortgage brokers or intermediaries correct answers to their questions and therefore reduce the manual workload of the customer services agents. Those agents get on average 150k questions per year.
We have gotten to a stage where we had a RAG prototype which was answering the questions, but we need to be able to evaluate how good our answers are live in a production setting where we don’t have the correct answer to compare the generated answer to.
After many trials and research on how this is done in the industry, we came up with a waterfall pipeline that is designed to be safe and flag correct answers which are hallucination‑free.
This pipeline is designed to fail safely and to abstain under uncertainty. It’s better to route too many questions to the agent than to send one incorrect, high‑confidence hallucination.
This post will be divided in two parts: the first part will talk about the pipeline or waterfall framework and explain its various components and how those components are implemented. The second part will take you through the results we got with the framework by running it on a set of test questions.
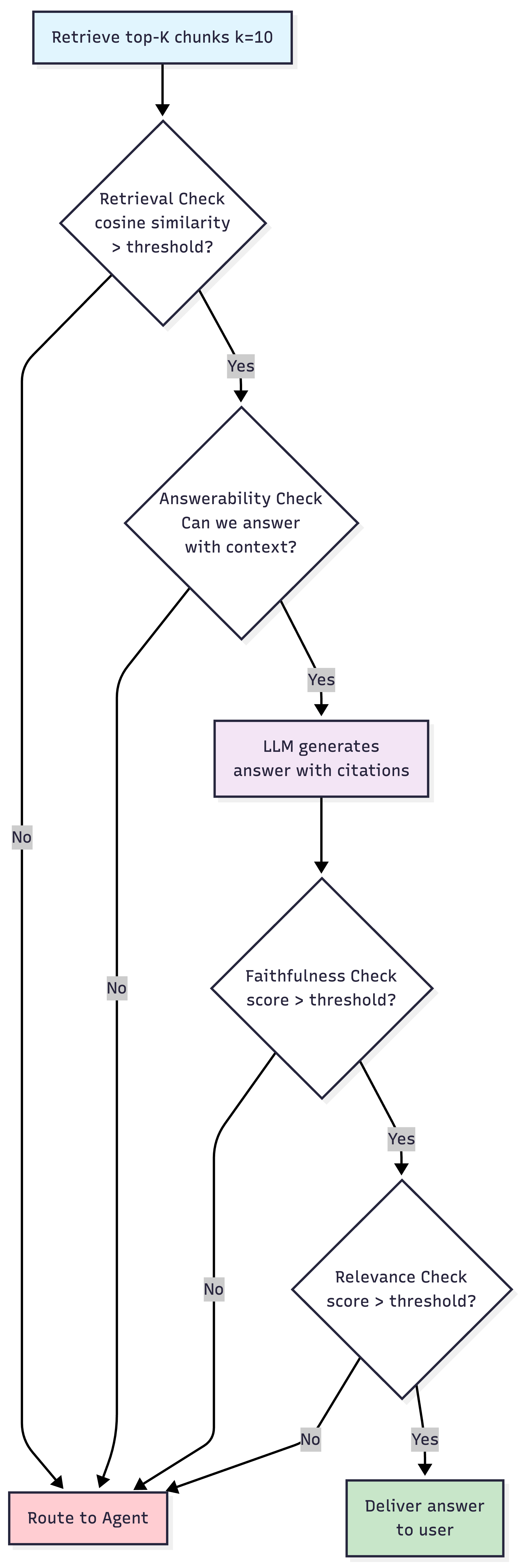
Evaluation Pipeline: Waterfall Framework.
Here’s what the pipeline looks like:
This post assumes that you are familiar with RAG and how it works. If that is not the case, I will recommend you to watch these videos they explains RAG in detail.
Layer One : Pre-Generation (Retrieval Checks)
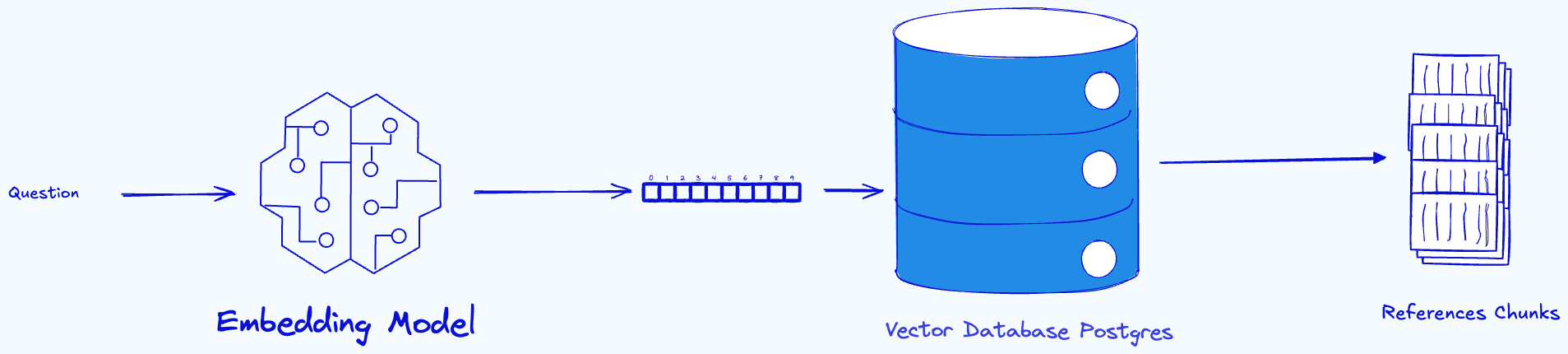
Retrieval Check
To answer a question, we compute its embedding vectors and then retrieve the references or chunks from the database using the cosine similarity between the question embeddings and the chunks embeddings.
The cosine similarity is a signal to tell if a chunk contains the answer to the question. A higher cosine similarity between the chunk and the question shows us that the chunk can contain the answer to the question, a lower cosine similarity shows that the chunk is not related to the question. In this step we retrieve the top K (k = 10) chunks sorted by cosine similarity.
This step checks cosine similarity between the highest‑ranked retrieved chunks and the question; if the similarity is lower than a threshold, that is a signal that we don’t have a chunk that contains the answer to the question. The threshold is a parameter of this system, it can be tuned. The chunking strategy we used, the embedding model we use, may affect the performance of this step.
Here is an example of the of the top 2 retrieved questions sorted by the cosine similarity for the following question Can you guys do day 1 remo?:
| content | cosine_similarity |
|---|---|
| Porting Applications: To port a product the new mortgage application must complete simultaneously with redemption of the current mortgage. The conveyancer must indicate a product is being ported when they obtain a redemption statement for the existing mortgage; the statement will then explain that the ERC does not need to be included in the redemption monies. | 0.389781 |
| Remortgaging with us - Welcome Call: It is important you advise the customer who the allocated conveyancer is and that they will receive a welcome call from them when the conveyancer will: Introduce themselves and explain they have been appointed to act as conveyancer on behalf of the bank. Provide an outline of next steps, including completion of the remortgage questionnaire and signature of the mortgage deed. Establish customers preferred method of communication throughout the remortgage transaction and encourage use of the conveyancing firm’s online customer portal. Discuss any potential complexities identified from the Land Registry (which they will have reviewed before the call) and set expectations around estimated timescales for completion. Notify the customer of the costs of any additional services payable by the customer. Answer any initial questions that the customer may have. | 0.389161 |
The question uses informal language (‘you guys’, ‘remo’) and the retrieved chunks, while mentioning remortgaging, don’t specifically address ‘day 1’ remortgages, resulting in low similarity scores
Note that these cosine similarity values of ~0.39 are relatively low (values closer to 1 indicate higher similarity), suggesting poor retrieval quality for this informal question
Alternatively, for this step if you have access to a re-ranker model, you can use a re-ranker model to compute the similarity between the questions and the retrieved chunked and use the re-ranker score to filter out the questions for which we don’t have similar chunks.
At the end of this step we are only dealing with questions for which we are sure that we have the chunks that can answer them.
Answerability Check
Given the question and the set of chunks or reference text, we need to find out if, based only on the following reference texts, it is possible to answer the question. This is a binary Yes/No task. If “No”, route to agent. This separates retrieval failure from generation failure.
Methods:
This check can be implemented by using two different approaches:
- The first one is to train a small, cheap classifier that can answer that question and output the binary response.
- The second one is to prompt an LLM and give it the question and the reference texts and ask it if, based only on the references, it is possible to answer the question. We used conditional generation and asked the model to return a binary response.
This metric can also serve as a proxy to the recall metrics commonly used in information retrieval where you have the golden reference chunk to a question.
With the remaining questions and the chunks we can now prompt our LLM to generate the answer to the question.
Layer Two: Post-Generation: Rich Checks
This is where we evaluate the actual generated answer.
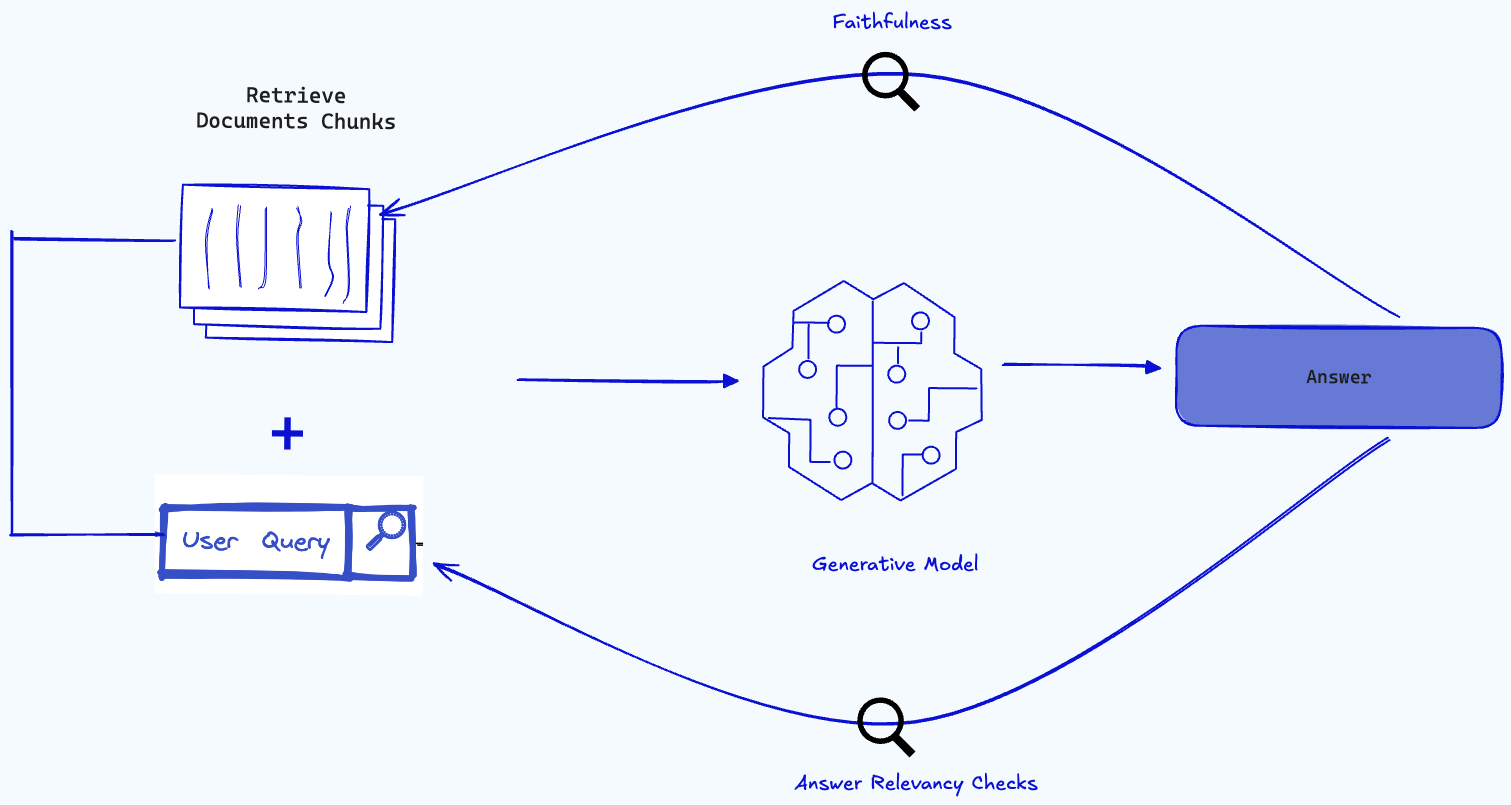
Faithfulness Check
Given the answer and the context used to generate it, the aim of this task is to find out if the answer is grounded in the context or supported by the context. This is the primary defence against hallucinations.
These types of checks are more expensive, but it is where we get the value for the system. Different methods are being developed in the industry to perform this type of task. Let’s highlight some of them:
Methods:
Natural Language Inference (NLI):
The natural language inference approach is used widely in fact verification. Given a fact and a bunch of reference text, can we find one reference that confirms or refutes the fact?
That same approach has been used in RAG evaluation. Given an answer and the context, the task similar to the NLI one is to check if the context supports or contradicts the answer. When the context contradicts an answer, we can say that the answer has been hallucinated.
To check, we use a model, we give it an answer or a claim from the answer, and a reference chunk, and then we compute the probability of contradiction between the answer and reference chunks. If that probability is higher than a threshold, we conclude that the answer is hallucinated and not grounded in the references.
The model used to compute the probability of contradiction can be a cross‑encoder model or a classification model trained on this type of task.
Models used in the industry:
- Currently Vectara have developed a model used based on the T5 transformer architecture:
- And the following model was used to compute the scores, it is Bert Model fine tuned on NLI task.
RAGAS Method:
In the RAGAS framework, a response is considered faithful if all its claims can be supported by the retrieved context.
To calculate this:
- We use an LLM to identify all the claims in the response.
- Check each claim to see if it can be inferred from the retrieved context. This can be performed using an LLM or NLI method with the claim and the reference.
- Compute the faithfulness score using the formula:
Example: If the answer states “Halifax offers 2-year and 5-year fixed mortgages,” the LLM would extract two claims:
- “Halifax offers 2-year fixed mortgages”
- “Halifax offers 5-year fixed mortgages” Each claim is then verified against the retrieved context.
LLM As a Judge:
This is a straightforward approach where we just prompt the LLM to check if the answer is grounded in any of the context.
With this approach use the following prompt:
You are a faithfulness evaluator assessing how truthful a response is to the provided context information.
TASK: Evaluate how faithfully the given answer represents information in the context without hallucination.
INPUTS:
Question: {question}
Context: {context_text}
Answer: {answer}
EVALUATION CRITERIA (equally weighted):
1. Factual Alignment: Does the answer only contain facts present in the context?
2. Completeness: Are all claims in the answer supported by the context?
3. Precision: Does the answer avoid adding details or interpretations not in the context?
SCORING GUIDE:
- 1-2: Answer contains significant hallucinations or contradicts the context
- 3-4: Answer contains some information not supported by the context
- 5-6: Answer is mostly faithful but includes minor details not in the context
- 7-8: Answer is faithful with very minimal unsupported information
- 9-10: Answer is completely faithful with all statements directly supported by the context
EDGE CASES:
- If answer contains paraphrasing but maintains factual accuracy, consider it faithful
- If context is ambiguous, be more lenient on faithful interpretation
- If answer includes common knowledge not in context, focus on whether it contradicts the context
Limitations of this method
The NLI methods are data science methods and all of them suffer from no‑free‑lunch theorems.
LLM as a judge are autoregressive generative models by nature; they cannot generate consistent responses between runs and are also prone to hallucination, we need to be careful in the choice of model we are picking here. One thing is to avoid using the same model for generation and evaluation.
NLI models, on the other hand, while they are less prone to hallucinations due to the fact that they are auto‑encoding models, are consistent with their output but sometimes lack domain knowledge due to the fact that they may not have been trained on the domains we are working with. It is recommended to fine‑tune a model on your own domain and use it for evaluation.
After this step, any answer that has at least one claim that is not supported by the reference is sent to an agent and we continue to the next step with the answers that are fully supported by their contexts.
Answer Relevance Checks:
This checks if the generated answer address the question. It measures how relevant a response is to the question, allowing us to find out if the generated answer is a direct response to the original query.
Methods:
Embedding Models
We can perform this by computing the embedding between the question and the answers. It is recommended to not use the same embedding model used for the retrieval to compute this cosine similarity.
RAGAS:
An answer is considered relevant if it directly and appropriately addresses the original question. This metric focuses on how well the answer matches the intent of the question, without evaluating factual accuracy. It penalizes answers that are incomplete or include unnecessary details.
This metric is calculated using the question and the response as follows:
- Generate a set of artificial questions (default is 3) based on the response. These questions are designed to reflect the content of the response.
- Compute the cosine similarity between the embedding of the question (Eo) and the embedding of each generated question (Egi).
- Take the average of these cosine similarity scores to get the Answer Relevancy:
If we expand the formula of the cosine similarity this is how it looks like:
\[Answer Relevancy = \frac{1}{N} \sum_{i=1}^{n} \frac{E_{gi} E_o}{||E_{gi}|| ||E_{o}||}\]Where:
- \(E_{gi}\): Embedding of the ith generated question.
- \(E_o\): Embedding of the user input.
- \(N\): Number of generated questions
The underlying concept is that if the answer correctly addresses the question, it is highly probable that the original question can be reconstructed solely from the answer.
LLM as a judge:
For this method an LLM is prompted with the question and the answer and asked to return a number which indicates how relevant the answer is to the question.
This approach use the following prompt:
You are an answer relevancy evaluator assessing how well answers address the original question.
TASK: Evaluate how relevant the given answer is to the question, regardless of factual accuracy.
INPUTS:
Question: {question}
Answer: {answer}
EVALUATION CRITERIA (equally weighted):
1. Direct Addressing: Does the answer directly address what was asked?
2. Topic Alignment: Is the information in the answer relevant to the question's topic?
3. Focused Response: Does the answer avoid unnecessary tangents or irrelevant details?
4. Completeness: Does the answer address all aspects of the question (if multi-part)?
SCORING GUIDE:
- 1-2: Answer is completely off-topic or doesn't address the question at all
- 3-4: Answer is tangentially related but misses the main point of the question
- 5-6: Answer addresses the question but includes irrelevant information or misses parts
- 7-8: Answer is mostly relevant with minor unrelated details or slight incompleteness
- 9-10: Answer is perfectly relevant and directly addresses all aspects of the question
and output a score that show how the answer is relevant to the question.
This is the last step of our pipeline and at its end we will have an answer and this answer is finally sent to the user.
Choosing between methods depends on your constraints: NLI models offer consistency and speed, RAGAS provides detailed claim-level analysis, while LLM-as-judge excels at domain adaptability.
This post takes us through the process of evaluating a RAG pipeline, it illustrated a waterfall pipeline that can be used to evaluate the system and how each component of that pipeline can be implemented. The next post illustrates how those steps were implemented with a set of questions we got for our system and how we can quantify the business value of a RAG system. Stay tuned for it.
References:
- Hugging Face Blog — Autoregressive and Autoencoding Models Overview
- C. Manning, B. MacCartney . Modeling Semantic Containment and Exclusionin Natural Language Inference
- Ageno, A. Textual Entailment: Natural Language Inference Approaches.
- Milvus Blog — Detecting Hallucinations in RAG-Generated Answers.
- Vectara — Hallucination Evaluation Model (T5-Based Cross Encoder).
- Tals — ALBERT-XLarge VitaminC MNLI Model.
- Phillipe Laban et al. (2021). SummaC: Re-Visiting NLI-based Models for Factual Consistency Evaluation.
- Tanner Sorensen. (2024). Provenance Approach for Hallucination Detection in RAG Systems.
Disclaimer: This post describes general RAG evaluation methodologies learned during a project. All views are my own and do not represent my employer. No confidential or proprietary information is disclosed.
Comments